


November 29, 2023
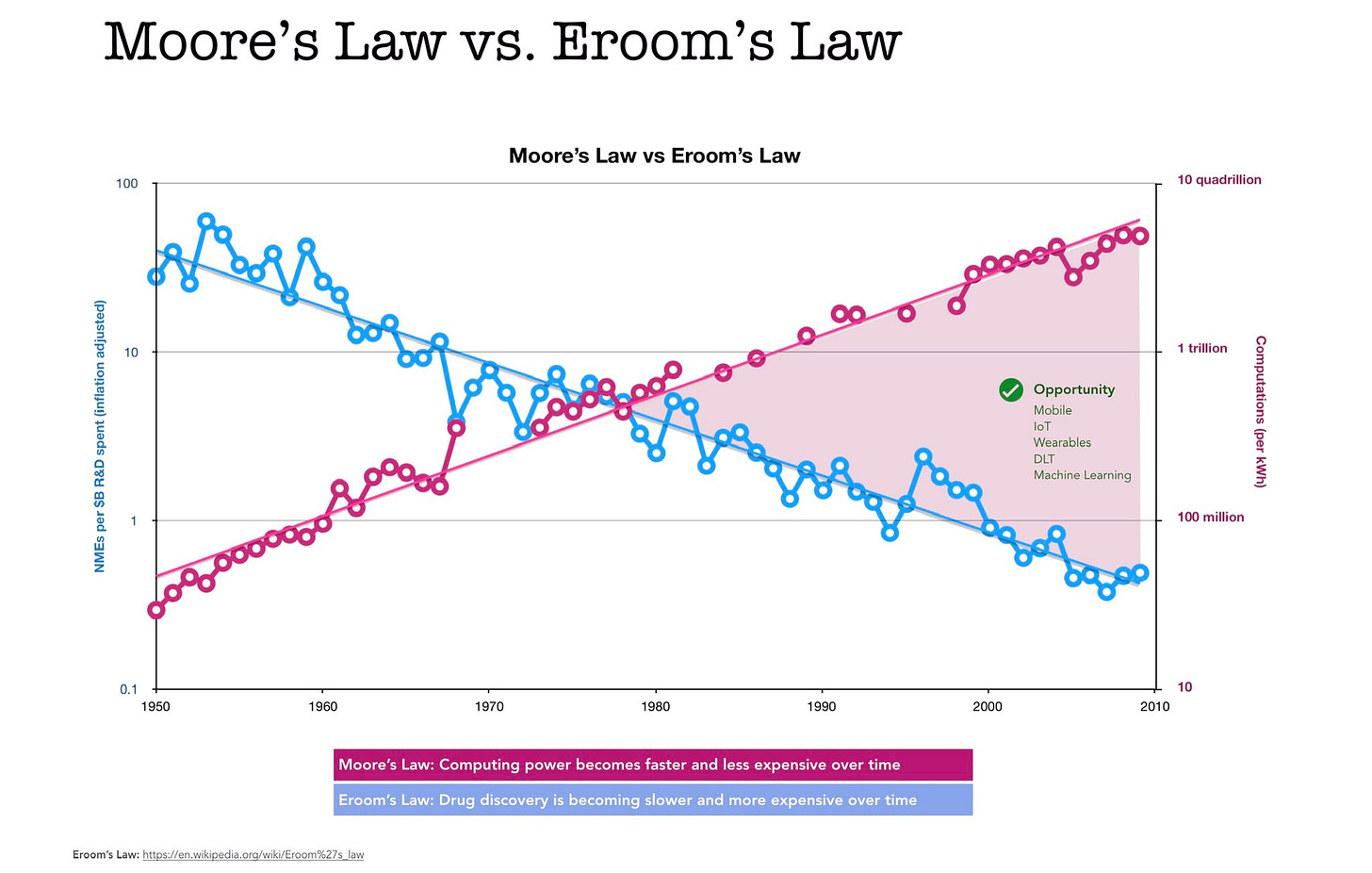
Moore's law is the observation that the number of transistors in an integrated circuit doubles roughly every two years so that new computers generally get both faster and cheaper over time. Eroom's law (Moore’s law, spelled backwards), by contrast, is the observation that drug discovery is becoming slower and more expensive over time, despite improvements in technology.
Even though continued gains in computing power through Moore’s law may be coming to an end, the technologies that it made possible are just coming to fruition—and will change everything about how we conduct biological and medical research. Eroom’s law has taken on an extinction debt and the clock is ticking.
One hallmark of physics is the remarkable precision with which we can predict many physical phenomena. Conversely, one hallmark of biology is the degree to which almost all biological phenomena are currently unpredictable. Some view this as a fundamental divide, but I disagree.
Most physical phenomena were unpredictable for the majority of human history. If you traveled back to the early 1600’s, you’d find that few physical phenomena were predictable at that time. Someone living before the 1600’s would likely have said that the phenomena we call physics are simply too complex to understand and predict. But, all that changed when Isaac Newton invented calculus. Mechanics, electrodynamics, relativity, and quantum mechanics all followed. Physical phenomena weren’t fundamentally unpredictable, we just lacked the tools until Newton came along.
So it is, I believe, with biology. The complexity of biological systems has seemed insurmountable simply because we’ve lacked the mathematical and computational tools to tame complex systems. Now we have them, and they’re called neural networks. Deep learning will have the same effect on biology that calculus had on physics.
Complex systems resist reductionism. It’s difficult, if not impossible, to describe the behavior of a complex system by modeling all of its underlying constituents. Just think about how many constituents one would need in a model of the human body: 20,000 protein coding genes being expressed in 37 trillion cells; and that’s already an abstraction because it’s not nearly an atomic level description!
Neural networks will revolutionize biological research because they can learn to predict the behavior of incredibly complex systems from data, even if those systems are too complex for humans to fully understand. However, the adoption of this new tool will require us to abandon reductionism in favor of macroscopic descriptions of complex biological systems. We will have the ability to predict patients’ future health outcomes with remarkable accuracy, but won’t know exactly what’s happening at the microscopic level to drive those changes. When the field fully grasps this, it will ignite a revolution.
There are three main reasons why the title of this post is in the future tense. Moore’s law will eat Eroom’s law, but it hasn’t yet. Why not?
First. It’s still early innings.
The technologies that have enabled training of large scale neural networks capable of learning to describe complex systems have, for the most part, been invented in the last two decades. It takes time for new technologies to develop and diffuse in order to gain adoption. That said, there are already some clear wins like Deepmind’s alphafold. The reductionist approach to protein folding—that is, trying to predict the folded structure of a protein using a physical model based on the interactions between its constituent atoms—hit a wall, stalled, and was leapfrogged by neural networks. The alphafold database now contains the predicted structures of more than 200 million proteins.
Second. The data are fragmented.
Data in biological and medical research haven’t routinely been collected for the purpose of training models or building quantitative theories. For example, databases of genomic data are rarely linked to detailed clinical data. Databases with detailed clinical data typically don’t contain large quantities of genomic, imaging, or digital biomarker data. Electronic health records databases contain a small amount of data on a large number of patients, whereas traditional research studies collect a large amount of data on a small number of participants. People often talk about data silos in medicine, which suggests that there are various institutions that have the data if only they would share it, but it’s actually worse than that. Realizing the potential of AI in medicine will require the specific collection, integration, and harmonization of all of these types of data for large cohorts with the goal of building training sets for AI models. This will be difficult, but it will happen.
Third. Resistance is alive, but it’s futile.
One of the biggest barriers to the computational transformation of biological and medical research—and the end of Eroom’s law—is cultural. Many clinical and biological researchers are unfamiliar with, and skeptical of, artificial intelligence, or view it as a subfield of something like bioinformatics instead of its own area of expertise. But this will pass. Artificial intelligence with remarkable capabilities is coming, and biopharma companies will be transformed just like everyone else.
What I’m suggesting—and what I believe is inevitable—is a redefinition of what it means to do biological research. Reductionism has to die in order for Eroom’s law to die. Rather than trying to isolate the effect of a gene or perturbation, in the future, biologists will think of how to collect experimental data in order to train neural networks. Science will become the construction of the training set. Scientists will become the teachers rather than the students.
Abandoning reductionism in biology is going to be really difficult, much like the adoption of large language models has been challenging for the field of linguistics. However, it’s hard to deny that language understanding and generation have been essentially solved by neural networks, with little help from traditional linguistics along the way. The future of these scientific fields will be shaped by those who embrace these new tools and adjust their research paradigms, not those who cling to current approaches.
Eroom’s law isn’t an inevitable consequence of the complexity of biological systems; rather, it persists because we haven’t yet developed the mathematical and computational tools to tame that complexity. I believe that neural networks are exactly that—the missing mathematical tool that will allow us to create predictive theories of the most complex biological systems. Once we overcome the current skepticism and resistance, and start to collect the integrated data needed to train these AI models in earnest, it will be a matter of time. Even though the picture I’ve painted of the future may be unfamiliar, the promises include more medicines, better medicines, and at cheaper prices.
That’s a future worth the discomfort of a paradigm shift.



